Being so interested in React, I wanted to create something useful, not just a Hello World, but something that depends on an API, with data. I had a little project that would be to scrape data from a website every day, and render some tables and graph from them.
We’ll explore how to create an API that returns data we previously scraped from the web, that we stored in a database. We’ll use nodejs^[Back then, in Feb 2015, I barely used it.] for the server and scrapper. For the database, we’ll keep it simple and use NeDB. Because I was going to have some many rows later (>300k), I would need a migration plan: NeDB has the exact same syntax as MongoDB which can handle millions of documents, we’ll check this out.
Summary
A nodejs server to expose an API
We’ll create a tiny server using nodejs that will serve some html pages, and also expose an API to contact the database.
We first install NodeJS, click click, done.
Following their example, we create a new folder: my-super-app and a new file server.js that will be the entry point.
var http = require('http');
http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('Hello World\n');
}).listen(1337, '127.0.0.1');
console.log('Server running at http://127.0.0.1:1337/');$ node server.js
Server running at http://127.0.0.1:1337/Node allows us to run any application that is written in Javascript. It’s useful to create lightweight HTTP client but not only. We can run anything that is Javascript based.
There are a lot of libraries available, almost 400,000 in Dec-2016^[124,046 at the time of writing, Feb-2015]!
They are all available using npm install package-name (automatically installed with NodeJS, this is its package manager).
There is an official search engine https://www.npmjs.com/search?q=react but other exist: https://libraries.io/npm.
Recent version of NodeJS understand the modern Javascript (ES6/ES2015, and V8 “Harmony” unstable features).
With older versions of nodejs, they are available under a experimental flag only: node --use-strict --harmony server.js.
Here is a list of the features ES2015 brings: https://babeljs.io/learn-es2015/.
package.json and dependencies
Nodejs needs a file package.json to write some metadata about our application. (name, description, version, dependencies)
We have to create it on the root of our project and must contains at least an empty JSON object {}.
More details here https://docs.npmjs.com/files/package.json.
It’s possible to create it automatically by typing npm init -y. It’s a small console wizard that will ask us a few things (if we don’t add -y) and automatically generates it.
Dependencies (which are the packages we need to run the whole application) are installed into the node_modules folder in our project root.
We can install new one by doing npm install [package], that will add files into this folder :
$ npm install timeago --save
timeago@0.2.0 node_modules\timeagoThis installs timeago plugin (which converts a Date to a sentence such as 3 days ago).
It’s source code is now in node_modules/timeago.
--save is used to add this package to our dependencies listed in package.json:
{"dependencies": { "timeago": "^0.2.0" }}How to use it ? We can use the require function that nodejs understands:
var timeago = require('timeago');
console.log(timeago(new Date))We can also add dependencies globally on our computer to avoid to reinstall them each time in our application^[Be careful, because if someone install your thing on its computer, it may not have this dependency installed. Consider it as a bad practice.]:
$ npm install --global [package]If we want to distribute our library/application, we don’t need to copy the node_modules: anybody with npm can recreate it thanks to package.json which list all the dependencies. Just typing npm install in the folder installs them.
Facebook has created a alternative to npm: yarn. Mostly compatible, it is still using package.json but it is way faster to install the dependencies.
expressjs as web framework
express is a web framework, and is higher level than the raw http.createServer() we used.
$ npm install --save expressjsvar express = require('express');
var app = express();
app.get('/:message', function (req, res) {
res.send('Hey ! You sent me <b>' + req.params.message + '</b>');
})
app.listen(3000)That is more human readable.
We can define routes with parameters. expressjs automatically deals with the querystring, and body data. There are a lot of plugins that can automatically do magic on the request and the response: they are called middlewares.
expressjs is a pipeline :
Input (request) -> Middleware1 -> Middleware2 -> Middleware3 -> Output (response).Every output is passed to the next middleware as its input. (this is the command pattern)
We can find this kind of expressjs initialization easily in projects:
// log requests to the console output
app.use(morgan('combined'));
// serve the icon the browser displays in the tab
app.use(favicon(__dirname + '/public/favicon.ico'));
// serve the `public/` folder content as a static resource (just returns the raw files inside)
app.use(express.static('public'));
// simulate DELETE and PUT calls if the client is using `X-HTTP-Method-Override`
app.use(methodOverride());
// parse `req.headers.cookie` (raw string) into `req.cookies` (keys -> values)
app.use(cookieParser());
// parse `application/x-www-form-urlencoded` form data into `req.body` (keys -> values)
app.use(bodyParser.urlencoded({ extended: false }));
// create a user session available in `req.session` (creates a cookie in the browser with an uuid)
app.use(session({ secret: 'your secret here' }));A lot is happening when a request takes place before going into our handlers.
How to create a web scraper?
We want to scrap some data on this url once every day.
This contains a table with some <td>, a name and a score.
We need to:
- request this url
- grab the content (html)
- parse it
- save it into a DB.
For the parsing, we’ll use something like jQuery but more adapted to nodejs: cheerio.
var express = require('express');
var request = require('request');
var cheerio = require('cheerio');
var url = 'http://jsbin.com/vusiwerana/3';
request(url, function(error, response, html) {
var $ = cheerio.load(html); // html is the raw response string : "<html><head>.."
var data = [];
$("tbody tr") // find every <tr> in this html
.each(function() {
var name = $(this).find('td.name').text(); // grab the 'name' cell
var score = $(this).find('td.score').text(); // grab the 'score' cell
data.push({ name: name, score: score });
});
console.log(data);
});$ node test.js
[ { name: 'John', score: '48' },
{ name: 'Henry', score: '19' },
{ name: 'ALbert', score: '15' } ]I got what we wanted.
Save the data inside a database: NeDB
Now, let’s add that into a DB for future usages. As we said earlier, we’ll use NeDB because it’s very easy to start with:
var neDB = require('nedb');
var db = new neDB({ filename: 'my.db', autoload: true });
request(url, function(error, response, html) {
// ...
console.log(data);
db.save(data); // append our list of objects to our database
});NeDB creates my.db file and append our objects inside. It automatically add a _id field:
{"name":"John","score":"48","_id":"8jhG83VQgD33489B"}
{"name":"Henry","score":"19","_id":"boUDzilITNM8rvq4"}
{"name":"ALbert","score":"15","_id":"medlEfshJ138ZIvM"}NeDB only handle objets, not simple types such as string or number, otherwise it will fail:
{ "message": "Can't insert key undefined, it violates the unique constraint",
"key": undefined,
"errorType": "uniqueViolated" }We can request our data anytime :
db.find({ name: 'John' })
.exec(function(err, result) {
if (err) {
console.error(err);
} else {
console.log('Got results: ', result);
}
});Got results: [ { name: 'John', score: '48', _id: '8jhG83VQgD33489B' } ]NeDB supports select, insert, delete, update operations. It handles indexes, unique constraints, sorting and paginating, and much more!
Check out its github, it has all the needed information and 5k stars.
Aparte: what about MongoDB?
If we wanted, we could already plugged in MongoDB into our code.
The code would be the same, except for the connection part (it’s not a simple file anymore).
We’ll use mongoose to talk to MongoDB in nodejs^[Note that alternatives exist, like the official client node-mongodb].
It’s more verbose than NeDB because there is some networking, and a schema of the data must be created. We also wait for the DB connection to be opened before exposing our HTTP application.
var mongoose = require('mongoose');
mongoose.connect('mongodb://localhost:27017/');
var ScoreModel;
var db = mongoose.connection;
db.on('error', function(e) {
console.error('connection error:', e);
});
db.once('open', function(callback) {
// we must define the "Schema" of our data to grab a "Model" (to save items)
var Schema = mongoose.Schema;
var scoreSchema = new Schema({ name: String, score: Number });
ScoreModel = mongoose.model('Score', scoreSchema);
// the connection to the DB is okay, let's start the application
app.listen(8080);
});
// ...
// We can't do just "db.save(obj)" now, we must encapsulated the data
function save(name, score) {
var newScore = new ScoreModel({ name: name, score: score });
newScore.save(function(err) { console.error("Error while saving: ", err); });
}Scrap multiple pages simultaneously
We want to scrap more than one page. Let’s say I have 10 pages to scrap on the same website. We won’t do a basic loop on the urls and issue a new request for each of them (we could but we won’t !).
Because of the impact, we would like to query 3 pages max at once. We can feel some asynchronous complexity in there. Hopefully, we are not the first who wants to do that. There is a wonderful library to help us: async. It can run multiple tasks in parallel, handle parallel limits and much more.
// we define our task (we give it a number to log it)
var callMe = function(taskNumber) {
// async passes us a function we can call when the task are done
return function(callback) {
var time = ~~(Math.random() * 1000); // random between 0 and 1000
console.log(new Date().getSeconds() +
'.' + new Date().getMilliseconds() +
' - starting task: ' + taskNumber);
// just waiting a random time before notifying async
setTimeout(function() {
// we can pass the task result to async that will give us them back at the end
callback(null, { task: taskNumber, time: time });
}, time);
};
};
// we create multiple tasks
var taskCount = +process.argv[2] || 10;
var tasks = _.range(taskCount).map(function(i) { return callMe(i); });
// tasks = [callMe(0), callMe(1), ... callMe(10)]
// nothing happened yet (callMe() returns a function), we start the processing now
// we defined a maximum concurrency at 2 tasks at the same time
async.parallelLimit(tasks, 2, function(error, result) {
console.log(result);
});$ node test.js 5
8.206 - starting task: 0
8.206 - starting task: 1
8.310 - starting task: 2
8.373 - starting task: 3
8.944 - starting task: 4
[ { task: 0, time: 927 },
{ task: 1, time: 110 },
{ task: 2, time: 61 },
{ task: 3, time: 556 },
{ task: 4, time: 520 } ]Few things here:
_.rangecomes from lodash (_). Every Javascript project uses it because it has so many useful tools.process.argv[2]is the program arguments from the command line- Tasks take a random time to execute. When done, they must call
callbackwhich is the argument passed byasyncto the function, to know when the task is done. It takes 2 arguments :errorandresult. If the task sends out an error,asyncstops and triggers thecompletecallback (the 3rd argument ofparallelLimit). If the task was successful, we have to send anullforerror. - In the
parallelLimitcomplete callback,resultis an array and contains what the tasks sent.asyncguarantees the order of the items to be the same order as the tasks.
Back to our problem, we want to scrape 10 pages in parallel, we follow the recipe :
var getLinksFromPage = function(pageNumber) {
return function(callback) {
request('http://www.example.com/page/' + pageNumber, function(error, response, html) {
var $ = cheerio.load(html);
var links = $("a").map(function() { return { link: $(this).attr('href') }; }).get();
db.insert(links, function(error) {
console.log(error);
});
});
};
};
// create 10 tasks to scrape 10 pages, with a maximum of 3 simultaneously
var scrapTasks = _.range(10).map(function(i) { return getLinksFromPage(i); });
async.parallelLimit(scrapTasks, 3, function(error, result) {
console.log(result);
});We have the scraping process, and the database.
We’ll do a small webservice to expose the data that the front-end will use.
Expose the data through the API
We’ll add a route http://localhost:3000/data to expose our data:
app.get('/data', function(req, res) {
// - look in the database for all records which property "link" contains "policies"
// - order them alphatically
// - and takes the first 10
var data = db.find({ link: { $regex: /.*policies.*/ } })
.sort({ link: 1 }) // 1 means ascending
.limit(10)
.exec(function(err, result) {
res.send(result);
});
});Note that we are using the $regex operator, because there is no simple $contains operator in NeDB/MongoDB.
Calling /data executes the query and wait. When the answer is back, exec is called and we send it to the brower (we have access to res because it’s in the outer scope).
Notice that the Javascript object result is automatically serialized into a JSON string and the Content-Type of the response is automatically set Content-Type: application/json; charset=utf-8.
After scraping some Google pages, we can have this result:
[{"link":"/intl/fr/policies/privacy/","_id":"RW0qTZ8CoZBlW77m"},
{"link":"/intl/fr/policies/privacy/","_id":"VUUJDM78V77KoFdw"},
{"link":"/intl/fr/policies/terms/","_id":"tUWqDKuYoDBDIx2u"},
{"link":"/intl/fr/policies/terms/","_id":"wLzt5gfyDh3ydPny"}]We are done with the server side.
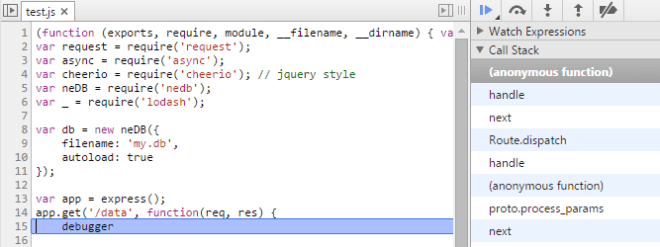
Aparte: How to debug NodeJS
In the browsers, we can debug with the available Developer Tools and the console. When an exception occurs, the browser can stop us directly where it happens. We can use debugger in our code to stop where we want (or still do some alert(), let’s face it).
Multiple solutions exist to debug with NodeJS.
- We can debug in the console using
node debug server.js. We can go through each line, watch variables, put breakpoints etc. But that’s a bit hardcore. More info here.
$ node debug test.js
< debugger listening on port 5858
connecting... ok
break in C:\Temp\test\test.js:1
1 var express = require('express');
2 var request = require('request');
3 var async = require('async');
debug>- We can use node-inspector.
We can have the full webkit debugger UI (the Developer tools) which is very good.
As in the browsers, we can use debugger to stop where we want.
To do that, we need to do 2 things :
- start
node-inspectorwhich handles the debugging UI :
$ node-inspector --web-port=8200 test.js
Node Inspector v0.5.0
info - socket.io started
Visit http://127.0.0.1:8200/debug?port=5858 to start debugging.- open a browser (a webkit one, Chrome or Opera) and go to http://localhost:8200/debug
We get the error: Error: connect ECONNREFUSED. Is node running with --debug port 5858 ? because it has nothing to debug for now.
We start our application in debug mode (notice --debug and not just debug):
$ node --debug test.js
debugger listening on port 5858We can refresh our browser. Done.
Conclusion
Our little API is done and we have a better experience with nodejs.
From scratch, we know how to make an application that has a database and exposed some webservices, all powered by nodejs. We know how to do a web scraper, grab the data we want, and save them.
