We had a table with a lot of regions (almost a thousand) dispatched on ~ten Region Servers. It means each RS handled 100 regions: more than we wanted, and more than it should, according to the HBase book. (memory pressure, compactions, MapReduce processes are split per region)
The max size of the HFile hbase.hregion.max.filesize was set to 10G.
We raised it to 20G and recompact the whole table. Nothing happened. Why ?
Because HBase does not merge regions automatically. We had to do it manually.
This article explains what’s going on under the hood of merges.
Summary
Why should we merge regions?
The HBase (minor) compaction process is used to merge Storefiles into a HStore (there is one HStore per column family, per region). A compaction never compact two regions together, it works on a same region.
The only processes that modify region boundaries are split and merge.
We’ll see how merge work with and without modifying hbase.hregion.max.filesize (to create bigger regions or not) by looking at HDFS.
For reference: HBase: 1.0.0-cdh5.4.7, Hadoop: 2.6.0-cdh5.4.7.
First tentative: merging with the 10G limit
Region names are just uuids
Merge only works with 2 consecutive regions.
The consecutivity is important, but you can also merge regions that are not consecutive. Although it’s not recommanded because that creates some overlapping regions.
If you have 2 regions whose start/end keys are 0-9 and 9-A, you may want to create a region whose start/end keys are 0-A.
In HDFS, the HBase regions are stored generally in /hbase/data/default/my_table.
All we can find in there are folders named with guids, that does not correspond to our keys.
To know what they are referring to, one way is to go to the HBase admin and select the table.
That will display all the regions name, uuid, start/end keys. http://hbase:60010/table.jsp?name=my_table (:16010 on recent versions)
An item would be:
my_table,0115d0b6f99f58a34...2a9e72781c7,1440840915183.fbb00c100422d1cc0f9b7e39d6c6bd91.The signification of the content is:
[table],[start key],[timestamp].[encoded ID].That gives:
table: my_table
start key: 0115d0b6f99f58a34...2a9e72781c7
timestamp: 1440840915183
encoded ID: fbb00c100422d1cc0f9b7e39d6c6bd91The encoded ID is what we are interested into.
This correspond to the folder in HDFS /hbase/data/default/my_table/fbb00c100422d1cc0f9b7e39d6c6bd91 where the data of this region are.
What’s going in HDFS when we merge regions?
Because we are going to merge consecutive regions, we look at the admin and get the next region UUID, then process to the merge:
hbase> merge_region 'fbb00c100422d1cc0f9b7e39d6c6bd91', 'a12acd303c0b7e512c8926666c5f02eb'That creates a new region 65bd... that contains a HFile which size is growing slowly, as we can see in HDFS
(here is a diff from before and after the merge_region):
+ 0 2015-12-23 12:24 /my_table/65bd..
+ 226 2015-12-23 12:24 /my_table/65bd../.regioninfo
+ 0 2015-12-23 12:24 /my_table/65bd../.tmp
+ 2684354560 2015-12-23 12:24 /my_table/65bd../.tmp/752530e58ae8478d812696b066edcc9f
+ 0 2015-12-23 12:24 /my_table/65bd../recovered.edits
+ 0 2015-12-23 12:24 /my_table/65bd../recovered.edits/2206186528.seqid
+ 0 2015-12-23 12:24 /my_table/65bd../t
+ 109 2015-12-23 12:24 /my_table/65bd../t/ccd883e710664f1fbf605590deaf2868.a12a..
+ 109 2015-12-23 12:24 /my_table/65bd../t/e17b4ea9b9fa47c1839999426ef9ffe7.fbb0..
- 0 2015-12-23 12:13 /my_table/a12a../recovered.edits
- 0 2015-12-23 12:13 /my_table/a12a../recovered.edits/2198106631.seqid
---
+ 0 2015-12-23 12:24 /my_table/a12a../recovered.edits
+ 0 2015-12-23 12:24 /my_table/a12a../recovered.edits/2198106637.seqid
- 0 2015-12-23 11:45 /my_table/fbb0..
---
+ 0 2015-12-23 12:24 /my_table/fbb0..
+ 0 2015-12-23 12:24 /my_table/fbb0../.merges
- 0 2015-12-23 12:13 /my_table/fbb0../recovered.edits
- 0 2015-12-23 12:13 /my_table/fbb0../recovered.edits/2206186546.seqid
---
+ 0 2015-12-23 12:24 /my_table/fbb0../recovered.edits
+ 0 2015-12-23 12:24 /my_table/fbb0../recovered.edits/2206186549.seqidWhat we can see:
- There is a new folder
65bd...that contains a HFile in.tmp(2.7GB, growing) and a.regioninfofile that contains the metadata to identify what is this region. - It also contains HFiles in
t/whose references the regions we merged (a12a..andfbb0..) - There is a new empty folder
.mergesin the first region we used to merge. - About all the
recovered.editsfolders: we won’t display them anymore. They are not important to our case. They are used to recover from failovers. For more info, check this nice Cloudera blog post to know more about it.
HBase automatically split regions
After a few minutes, it was done, the HFile grew up to 17GB (which was over the limit of 10GB) and the old regions a12a.. and fbb0.. were removed.
Then HBase started the reverse process: it split the big region we just made automatically (because the limit is 10G):
+ 0 2015-12-23 13:05 /my_table/2c14..
+ 226 2015-12-23 13:05 /my_table/2c14../.regioninfo
+ 0 2015-12-23 13:05 /my_table/2c14../t
+ 109 2015-12-23 13:05 /my_table/2c14../t/752530e58ae8478d812696b066edcc9f.65bd..
+ 0 2015-12-23 13:05 /my_table/65bd..
+ 226 2015-12-23 12:24 /my_table/65bd../.regioninfo
+ 0 2015-12-23 13:05 /my_table/65bd../.splits
+ 0 2015-12-23 13:05 /my_table/65bd../.tmp
+ 0 2015-12-23 13:05 /my_table/65bd../t
+ 17860937303 2015-12-23 13:05 /my_table/65bd../t/752530e58ae8478d812696b066edcc9f
+ 0 2015-12-23 13:05 /my_table/743b..
+ 226 2015-12-23 13:05 /my_table/743b../.regioninfo
+ 0 2015-12-23 13:05 /my_table/743b../.tmp
+ 134217728 2015-12-23 13:05 /my_table/743b../.tmp/e377603958894f8ca1ec598112b95bf4
+ 0 2015-12-23 13:05 /my_table/743b../t
+ 109 2015-12-23 13:05 /my_table/743b../t/752530e58ae8478d812696b066edcc9f.65bd..
- 0 2015-12-23 11:45 /my_table/a12a..
- 0 2015-12-23 11:45 /my_table/fbb0..What we can see:
- The split region has a
.splitsfolder (in the merge process, we had.merges) - 2 new regions appeared :
2c14..and743b.. - Only one of these 2 regions have a HFile that is slowly growing: here the region
743b...(look at its.tmp). It’s a sequential process.
We are going to fallback into our initial situation.
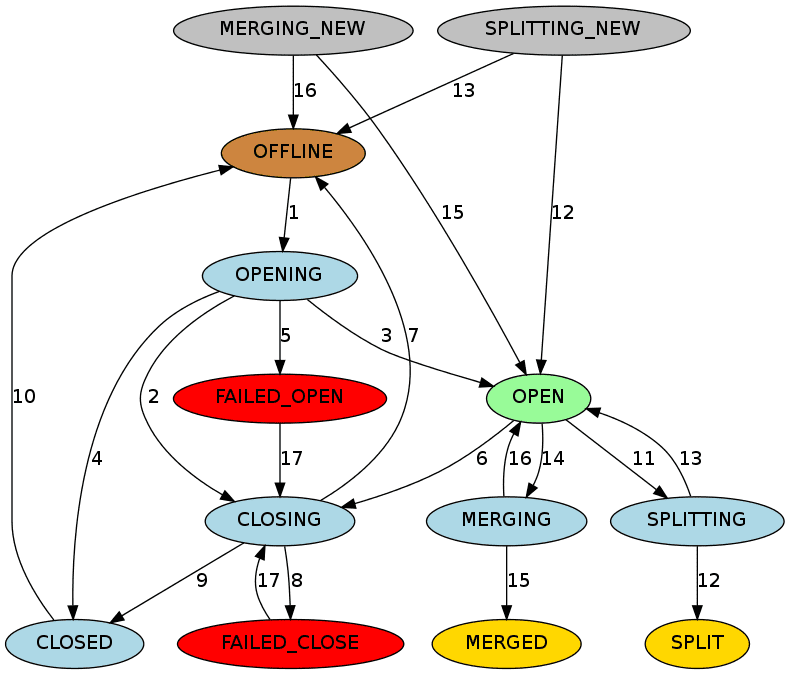
About the HBase region state transitions
In the logs, we can see that:
- The new regions state are set to
SPLITTING_NEW. - The split region is set to
SPLITTINGthenSPLITand took offline. - The new regions state are set to
OPEN(queryable and accumulate data). - The split region metadata are removed, sayonara.
// 2 new regions from a SPLIT
2015-12-23 13:05:32,817 INFO org.apache.hadoop.hbase.master.RegionStates:
Transition null to {2c142664dc0929d7c6cc5fa6fe3b4e40 state=SPLITTING_NEW, ts=1450872332817, server=hbase04,60020,1450869198826}
2015-12-23 13:05:32,817 INFO org.apache.hadoop.hbase.master.RegionStates:
Transition null to {743bfa035be56bf412d00803abe433b8 state=SPLITTING_NEW, ts=1450872332817, server=hbase04,60020,1450869198826}
// the region we are splitting was OPEN
// it goes to SPLITTING then SPLIT, and is set offline for the time being
2015-12-23 13:05:32,817 INFO org.apache.hadoop.hbase.master.RegionStates:
Transition {65bd82b5477fcc2090804c351d89700a state=OPEN, ts=1450869854560, server=hbase04,60020,1450869198826}
to {65bd82b5477fcc2090804c351d89700a state=SPLITTING, ts=1450872332817, server=hbase04,60020,1450869198826}
2015-12-23 13:05:34,767 INFO org.apache.hadoop.hbase.master.RegionStates:
Transition {65bd82b5477fcc2090804c351d89700a state=SPLITTING, ts=1450872334767, server=hbase04,60020,1450869198826
to {65bd82b5477fcc2090804c351d89700a state=SPLIT, ts=1450872334767, server=hbase04,60020,1450869198826}
2015-12-23 13:05:34,767 INFO org.apache.hadoop.hbase.master.RegionStates:
Offlined 65bd82b5477fcc2090804c351d89700a from hbase04,60020,1450869198826
// both 2 new regions switch from SPLITTING_NEW to OPEN
2015-12-23 13:05:34,767 INFO org.apache.hadoop.hbase.master.RegionStates:
Transition {2c142664dc0929d7c6cc5fa6fe3b4e40 state=SPLITTING_NEW, ts=1450872334767, server=hbase04,60020,1450869198826}
to {2c142664dc0929d7c6cc5fa6fe3b4e40 state=OPEN, ts=1450872334767, server=hbase04,60020,1450869198826}
2015-12-23 13:05:34,767 INFO org.apache.hadoop.hbase.master.RegionStates:
Transition {743bfa035be56bf412d00803abe433b8 state=SPLITTING_NEW, ts=1450872334767, server=hbase04,60020,1450869198826}
to {743bfa035be56bf412d00803abe433b8 state=OPEN, ts=1450872334767, server=hbase04,60020,1450869198826}
// daughter a and b = new regions with start keys; the parent being the split region
2015-12-23 13:05:34,873 INFO org.apache.hadoop.hbase.master.AssignmentManager:
Handled SPLIT event;
parent=my_table,fe7f...,1450869853820.65bd82b5477fcc2090804c351d89700a.,
daughter a=my_table,fe7f...,1450872332556.2c142664dc0929d7c6cc5fa6fe3b4e40.,
daughter b=my_table,feff...,1450872332556.743bfa035be56bf412d00803abe433b8., on hbase04,60020,1450869198826
// then the split region saw it reference in the metadata (zookeeper) removed
2015-12-23 13:08:28,965 INFO org.apache.hadoop.hbase.MetaTableAccessor:
Deleted references in merged region my_table,fe7f...,1450869853820.65bd82b5477fcc2090804c351d89700a., qualifier=mergeA and qualifier=mergeBThis follows the Regions State Transition graph:
What’s going in HDFS when we split regions?
After a while, HBase has filled the daughter region b 743b.., and starts filling the daughter region a 2c14...
Then at the end, we have:
+ 0 2015-12-23 13:25 /my_table/2c14..
+ 226 2015-12-23 13:05 /my_table/2c14../.regioninfo
+ 0 2015-12-23 13:41 /my_table/2c14../.tmp
+ 0 2015-12-23 13:41 /my_table/2c14../t
+ 8732040437 2015-12-23 13:41 /my_table/2c14../t/2388513b0d55429888478924914af494
+ 0 2015-12-23 13:05 /my_table/65bd..
+ 226 2015-12-23 12:24 /my_table/65bd../.regioninfo
+ 0 2015-12-23 13:05 /my_table/65bd../.splits
+ 0 2015-12-23 13:05 /my_table/65bd../.tmp
+ 0 2015-12-23 13:05 /my_table/65bd../t
+ 17860937303 2015-12-23 13:05 /my_table/65bd../t/752530e58ae8478d812696b066edcc9f
+ 0 2015-12-23 13:05 /my_table/743b..
+ 226 2015-12-23 13:05 /my_table/743b../.regioninfo
+ 0 2015-12-23 13:25 /my_table/743b../.tmp
+ 0 2015-12-23 13:25 /my_table/743b../t
+ 8733203481 2015-12-23 13:25 /my_table/743b../t/e377603958894f8ca1ec598112b95bf4The region 65bd.. has been successfully split.
After a few minutes, it is removed automatically from HDFS.
2015-12-23 13:43:28,908 INFO org.apache.hadoop.hbase.MetaTableAccessor:
Deleted my_table,fe7f...,1450869853820.65bd82b5477fcc2090804c351d89700a.
2015-12-23 13:43:28,908 INFO org.apache.hadoop.hbase.master.CatalogJanitor:
Scanned 722 catalog row(s), gc'd 0 unreferenced merged region(s) and 1 unreferenced parent region(s)If we compare the size of the daughter regions and the big one, we get a delta of +395MB (the single HFile is bigger).
To resume, we’ve successfully merged 2 regions into one, that was automatically split into two by HBase: a shot in the dark.
Second tentative: merging with a 20G limit
Now, we change hbase.hregion.max.filesize to 20G and merge again our regions.
We apply the same process than before and merge manually the 2 regions we got previously 2c14.. and 743b...
This creates a new region 1e64.. whose size is surprisingly lower than our previous merge (we only get a delta of 212KB).
HBase is going to split it because it only weights 17GB, while we have a limit of 20GB.
$ hdfs dfs -ls -R /hbase/data/default/my_table/1e64aa6f3f5cf067f6d5339230ef6db7
226 2015-12-23 13:45 /my_table/1e64.../.regioninfo
0 2015-12-23 14:12 /my_table/1e64.../.tmp
0 2015-12-23 13:48 /my_table/1e64.../recovered.edits
0 2015-12-23 13:48 /my_table/1e64.../recovered.edits/2206186536.seqid
0 2015-12-23 14:12 /my_table/1e64.../t
17465031518 2015-12-23 14:12 /my_table/1e64.../t/d1109c52de404b0c9d07e2e9c7fdeb5eOur fat region is there to stay and won’t be split.
We now have to automatize this to merge all small consecutive regions together.
Conclusion: hbck
Understanding what’s going on in HDFS with HBase is important when we are facing issues and errors in HBase table structure.
There is a tool hbck to analyze the HBase structure, that should be regularly launched and monitored:
$ hbase hbck my_tableWe can get ERRORS such as:
- No HDFS region dir found
- Region not deployed on any region server.
- Region found in META, but not in HDFS or deployed on any region server.
- First region should start with an empty key. You need to create a new region and regioninfo in HDFS to plug the hole.
- You need to create a new .regioninfo and region dir in hdfs to plug the hole.
- ERROR: Found lingering reference file hdfs://…
Those errors can happen quite easily unfortunately. I successfully ran into those issues just with by merging regions, not sure why.
