The previous part of this series: How to communicate between micro-services — Part 2 — Retryers.
We saw in the previous article the Retryer pattern which is quite simple but can be insufficient to be fully resilient.
A smarter pattern is the Circuit-Breaker. It’s smarter, because it has memory and a state. It’s a finite state machine. It avoids useless retries if it already knows they will fail, and can instantly provides a fallback. According to some thresholds, it will try once later to access the service or resource, to see if it’s back.
This is a pattern to use when a fallback is possible, like using another service, providing a default value, or something the program can handle without the expected response. If it’s not possible and the code need a external answer no matter what (like getting metadata), then the Retryer pattern fits better.
Summary
What is a Circuit Breaker?
A circuit-breaker is a finite state machine with 3 states:
- closed: the normal state, the external service or resource is accessible, no problem, as if the circuit-breaker were not there, it’s transparent.
- open (or tripped): the circuit-breaker knows something is broken and is failing. It provides a direct fallback, it won’t even try to make the external call.
- half-open: a very temporary state. The CB detected some failures, it will still test to see if it’s really broken or if it was just a temporary failure, and will quickly switch to closed or open.
A CB is highly tunable, thanks to the multiple configurable thresholds (by count, by timeouts).
With tiny thresholds, we can either fail fast to provide a quick feedback with an error, or we can provide a quick valid enough fallback.
The timeouts are explicits: it’s necessary when service are not down but slow. In some domains, it’s mandatory to provide responses under 100ms for instance (like in RTB), therefore a CB is generally used to be able to provide something quick no matter what.
A CB provides some kind of backpressure: the end service is slow because it’s overloaded? the CB will short-circuit it during a while, the time to recover, and will detect when it’s available again later.
Note that a circuit-breaker does not provide any retry logic. But we can still mix it with a Retryer if we want to force our way.
Martin Fowler has written a piece about it a few years ago.
Tuning parameters
Circuit-breakers have several thresholds and delays to tune their behavior, and how/when they changed their state.
There should not have defaults, because each circuit-breaker is dealing with a particular service call and situation. The circui-breaker must be tested and the impact measured. The latter can affect the business, can provoke more harm than good.
- Failures threshold: to open the circuit (won’t call the service again).
- Success threshold: to close the circuit (will call the service again).
- Function call timeout: a call can be consider as a failure if it took too much time.
- Open to Half-Open delay: to try again to call the service.
- Failure/Success conditions: we can indicate what is a failure (besides timeouts), more business oriented.
- State transitions: we can generally monitor those state changes. We must be aware when a circuit is opened.
Failsafe
We already used the Retryer of Failsafe in the previous part of this series. Let’s use their circuit-breaker now, to contact our brittle service.
libraryDependencies += "net.jodah" % "failsafe" % "1.0.1"CircuitBreaker cb = new CircuitBreaker()
.withFailureThreshold(2)
.withSuccessThreshold(2)
.withTimeout(500, TimeUnit.MILLISECONDS)
.withDelay(1, TimeUnit.SECONDS)
.failIf((Response r) -> r == null || r.getStatusCode() != 200);
cb.onClose(() -> System.out.println("Good enough, closing circuit"));
cb.onHalfOpen(() -> System.out.println("Will try again, half-opening circuit"));
cb.onOpen(() -> System.out.println("Too many failures, opening circuit"));
// Then our calls:
for (int i = 0; i < 10; i++) {
try {
Response response = Failsafe.with(cb).get(() -> getBilling());
System.out.println("response: " + response);
} catch (Exception e) {
System.out.println("ERR: " + e);
} finally {
System.out.println("circuit-breaker: " + cb.getState());
Thread.sleep(200); // just for the example, to get into the half-open state
}
}withFailureThreshold: we declare it’s broken (open the cb) if there are at least 2 consecutive failures.withSuccessThreshold: we declare it’s not broken anymore (close the cb) if there are at least 2 consecutive success.withTimeout: we consider that if the query takes more than 500ms, then it’s a failure (the call is still made to the end).withDelay: we do not try anymore during 1s if the circuit is opened. ie: we wait 1s before going to half-open state that will try again.failIf: the condition declaring if the call was a failure or success (besides the timeout).
We’ll try to make 10 calls to the external service and log each time the circuit-breaker state. We can see we pass through all states, how interesting! I’ve added some spaces and comments in-between:
// a circuit always starts closed and call our method.
>>> Calling external service...
ERR: net.jodah.failsafe.FailsafeException: java.util.concurrent.TimeoutException
circuit-breaker: CLOSED
>>> Calling external service...
ERR: net.jodah.failsafe.FailsafeException: java.util.concurrent.TimeoutException
Too many failures, opening circuit
circuit-breaker: OPEN
// the call was made twice, and failed twice (withFailureThreshold), hence the circuit is opened.
// when a circuit is opened, our method is not called anymore.
ERR: net.jodah.failsafe.CircuitBreakerOpenException
circuit-breaker: OPEN
ERR: net.jodah.failsafe.CircuitBreakerOpenException
circuit-breaker: OPEN
ERR: net.jodah.failsafe.CircuitBreakerOpenException
circuit-breaker: OPEN
ERR: net.jodah.failsafe.CircuitBreakerOpenException
circuit-breaker: OPEN
// 1s has passed (withDelay), the circuit-breaker will call our method again.
// It will switch to closed only if the success threshold is reached.
Will try again, half-opening circuit
>>> Calling external service...
response: com.ning.http.client.providers.netty.response.NettyResponse@47c62251
circuit-breaker: HALF_OPEN
>>> Calling external service...
response: com.ning.http.client.providers.netty.response.NettyResponse@3e6fa38a
Good enough, closing circuit
circuit-breaker: CLOSED
// and 2 calls have succeed (withSuccessThreshold)! Meaning the circuit is closed again.
>>> Calling external service...
ERR: net.jodah.failsafe.FailsafeException: java.util.concurrent.TimeoutException
circuit-breaker: CLOSED
>>> Calling external service...
ERR: net.jodah.failsafe.FailsafeException: java.util.concurrent.TimeoutException
Too many failures, opening circuit
circuit-breaker: OPEN
// Back to square one, 2 calls have failed again, the circuit is reopened.As we saw, Failsafe provides a quite good implementation. We have everything we need and the API is quite clear.
Sentries
In Sentries, circuit-breakers are more an implementation detail and are hidden behind the sentry concept. They are also simpler than in Failsafe for instance.
A sentry can wrap any function call (it’s a Higher Order Function), so any caller will first pass through the sentry before reaching the function code, if the sentry let it pass. A sentry is chainable: it’s composed by several other sentries that takes only one responsability, it’s a flow of sentries. And because it’s a flow: the order matters.
Sentry Builder -> Sentry with Fail Limit -> Sentry with Rate Limit -> [Code]If we use withFailLimit on a sentry, to trigger a circuit-breaker opening after N failures, this will actually append a CircuitBreakerSentry to our sentry. Internally, its state are: FlowState (closed) and BrokenState (opened): there is no concept of half-open.
If we take a simple example:
object ExternalService extends SentrySupport {
val client: AsyncHttpClient = new AsyncHttpClient
val billingSentry = sentry("billing").withFailLimit(failLimit = 2, retryDelay = 1 second)
def getBilling(url: String = "http://localhost:1234/billing") = billingSentry {
client.prepareGet(url).execute.get(1000, TimeUnit.MILLISECONDS)
}
}
println(Try(ExternalService.getBilling()))
println(Try(ExternalService.getBilling()))
println(Try(ExternalService.getBilling()))Failure(java.util.concurrent.TimeoutException)
Failure(java.util.concurrent.TimeoutException)
Failure(..CircuitBreakerBrokenException: Making billing unavailable after 2 errors)Thanks the sentry (and the cb), the 3rd call wasn’t made. One second later, it would let the call passed, to test them again.
Any call blocked by a sentry will thrown an exception such as CircuitBreakerBrokenException, ConcurrencyLimitExceededException, DurationLimitExceededException, according to which sentry was out of its limits.
Note that a failure is simply because an exception occurred. There is no means to plug in some callback to implement a custom business rule.
Sentries provides more features than just circuit-breakers:
withMetrics: Monitoring only. It provides metrics for successes/failures/sentry blocked.withTimer: Monitoring only. It provides the time passed in a function.withFailLimit: Breaks if there are more failures than expected. It will call the original function again after some delay.withAdaptiveThroughput: Try to ensure a given success ratio instead of prevent all calls if case of failures (like when it’s acceptable to have 95% of success and 5% of failures on big volumes).withConcurrencyLimit: Breaks if more thanconcurrencyLimitcalls the function at the same time.withRateLimit: Breaks if the function is called more than expected in a given time.withDurationLimit: Breaks if the function takes longer than expected.
The API of Sentries is easy, composable, but lack of some features like declaring a failure according to some custom predicate. The good point is the embedded metrics monitoring, exposed through JMX.

Akka
Akka is not to present anymore. It’s quite idiomatic in Scala nowadays.
It provides a full-featured circuit-breaker using a Akka Scheduler. It works mostly async-ly but supports sync calls (just by wrapping the call into a Future and Awaiting it).
Its API is quite similar to Failsafe’s.
Let’s manually trigger the success and the fail to make it go through the different states:
libraryDependencies += "com.typesafe.akka" %% "akka-actor" % "2.4.16"implicit val system = ActorSystem("app")
implicit val ec = system.dispatcher
val scheduler = system.scheduler
val cb = CircuitBreaker(scheduler,
maxFailures = 3,
callTimeout = 1 minute,
resetTimeout = 3 seconds)
cb.onClose(log("cb closed"))
cb.onOpen(log("cb opened"))
cb.onHalfOpen(log("cb half opened"))
log("1x failure"); cb.fail()
log("2x failure"); cb.fail()
log("3x failure"); cb.fail()
// we wait for the half-open state...
scheduler.scheduleOnce(5 seconds) {
log("task...")
// cb.fail() — The circuit would be reopened directly from the half-open state!
cb.succeed()
val fut: Future[Boolean] = cb.withCircuitBreaker { Future { true } }
val res: Boolean = cb.withSyncCircuitBreaker { true }
}0.770: 1x failure
0.782: 2x failure
0.782: 3x failure
0.784: cb opened
3.792: cb half opened
5.794: task...
5.795: cb closedThe advantage of the Akka circuit-breaker is that it’s dealing with Scala and Futures directly: it can be a Success or a Failure, that the circuit-breaker is relying to.
Thanks to this, we can easily provide a fallback value in case of a failure / circuit-breaker opened.
For instance:
val client: AsyncHttpClient = new AsyncHttpClient
def getBilling(url: String = "http://localhost:1234/billing"): Future[Response] = {
Future { blocking { client.prepareGet(url).execute.get(1000, TimeUnit.MILLISECONDS) } }
}
...
val responsesF = Future.sequence((1 to 10).map { _ =>
// getBilling can throw a TimeoutException
cb.withCircuitBreaker { getBilling().map(_.getStatusCode) }
.fallbackTo(Future.successful(1337))
})
val status: Seq[Int] = Await.result(responsesF, Duration.Inf)
println(status)Vector(1337, 1337, 1337, 1337, 1337, 1337, 200, 1337, 1337, 1337We may wonder why can we find a 200 at the 7th position, because the circuit-breaker should be opened at the 3rd failure!?
All the function calls were executed at the same time in the loop here; the circuit was still closed at the call time, because no response was back yet.
We can simulate a real-word simulation by reducing our request timeout and introducing some lag:
def getBilling(url: String = "http://localhost:1234/billing"): Future[Response] = {
println("getBilling")
// 100ms max
Future { blocking { client.prepareGet(url).execute.get(100, TimeUnit.MILLISECONDS) } }
}
...
val responsesF = Future.sequence((1 to 10).map { _ =>
// we simulate a call every 120ms
Thread.sleep(120)
cb.withCircuitBreaker { getBilling().map(_.getStatusCode) }
.fallbackTo(Future.successful(1337))
})getBilling
getBilling
getBilling
getBilling
getBilling
cb opened
Vector(1337, 200, 1337, 1337, 1337, 1337, 1337, 1337, 1337, 1337)The circuit-breaker is opened at the fifth call (3rd failures in a row) and the function is not called anymore.
As we want see, this circuit-breaker is not really related to Akka and the Actor model and could be used anymore. Its only dependency is the Akka Scheduler, which is used to:
- Control the function invocation time and throw a Failure if it’s greater than the
callTimeout. - Switch from the opened state to the half-open state after the given
resetTimeout.
Hystrix
Hystrix by Netflix is a popular choice.
It’s a framework (written in Java) dedicated to applications resilience, by wrapping every commands into a HystrixCommand, that provides much more than just a circuit-breaker.
Netflix team are experts in the domain of services communication and (voluntary) outages! (Chaos Monkeys anyone?) It’s also the one Spring recommends to use. Someone even translated the circuit-breaker piece to Javascript: circuit-breaker-js.
HystrixCommands are the heart of Hystrix:
- They are all protected by a circuit-breaker, a max timeout, a max concurrency threshold.
- They can have a fallback.
- Calls are automatically logged and monitored.
- Results can be cached.
- Multiple commands can be collapsed into one to improve the throughput.
Hystrix also provides a lot of options to tune the concurrency of the commands (with threads pools or semaphores).
Note that the responses are backed by Observables, it’s better to know how to use them.
Small downside: I find the framework quite verbose. It’s not that easy to navigate around all the classes and helpers to know which one to use.
Commands
Here is an example of a GetBilling command with more properties than it should have, but it’s simply to feel the power:
libraryDependencies += "com.netflix.hystrix" % "hystrix-core" % "1.5.9"class GetBillingCommand(billingUrl: String) extends HystrixCommand[Response](
HystrixCommand.Setter
.withGroupKey(HystrixCommandGroupKey.Factory.asKey("billing"))
.andCommandKey(HystrixCommandKey.Factory.asKey("get-billing"))
.andCommandPropertiesDefaults(
HystrixCommandProperties.Setter()
// allow 2 concurrent access only
.withExecutionIsolationStrategy(ExecutionIsolationStrategy.SEMAPHORE)
.withExecutionIsolationSemaphoreMaxConcurrentRequests(2)
// throw a HystrixTimeoutException if the function call takes more than 200ms
.withExecutionTimeoutEnabled(true) // default true
.withExecutionTimeoutInMilliseconds(200) // default 1000
// the circuit-breaker (and rolling metrics) work in a window split in buckets
// - we ask a window of 10s split into 100 buckets (0.1s each)
.withMetricsRollingStatisticalWindowInMilliseconds(10000) // default 10s
.withMetricsRollingStatisticalWindowBuckets(100) // 1 bucket=100ms, default 10
// by default, circuit-breaker are enabled
// - open it if 10% of the requests failed in the window
// - let it open during at least 1s before retrying
// - 10 requests in 10sec must be executed to matter
.withCircuitBreakerEnabled(true) // default true
.withCircuitBreakerErrorThresholdPercentage(10) // default 50(%)
.withCircuitBreakerSleepWindowInMilliseconds(1000) // default 5000ms
.withCircuitBreakerRequestVolumeThreshold(10) // default 20
)) {
override def run(): Response = {
client.prepareGet(billingUrl).execute
}
override def getFallback: Response = {
new Response.ResponseBuilder().build() // dummy response
}
override def getCacheKey: String = "get-billing"
}
// Most commands needs a context to store cached values, requests, stats...
val context = HystrixRequestContext.initializeContext()
val response: Response = new GetBillingCommand("http://service:8081/billing").execute
val responseF: JFuture[Response] = new GetBillingCommand("http://service:8081/billing").queue
// responseF.cancel(true)
...
println("Requests => " + HystrixRequestLog.getCurrentRequest().getExecutedCommandsAsString)
// Requests => GetBillingCommand[TIMEOUT, FALLBACK_SUCCESS][232ms],
// GetBillingCommand[TIMEOUT, FALLBACK_SUCCESS, RESPONSE_FROM_CACHE][0ms]x22
context.close() // avoid a memory leakA lot of general things to note:
- The
Setterthings are the way to build up things in Hystrix. They follow a builder pattern (ok, without the.build()) to provide a fluent interface to configure objects:

- The
GroupKeyis the way to group commands (to display them together for instance). - The
CommandKeyis the “name” of the command. It defaults to the class name, so it’s optional. - All the properties have already a default value, no need to override every one of them.
- A
HystrixRequestContextmust be initialized when a request occurs. All threads later will refer to the current context to store some data (we can see it as a static global variable, omg). HystrixRequestLogcan be queried to get some stats about the commands played in the current context.- A command must override the
run()method. This is the code that will be executed (or short-circuited), that can fail or timeout. - A command can override the
getFallbackmethod in caserun()fails or is short-circuited. When no fallback is provided and a failure occurs, an exception is thrown:
Exception in thread "main" com.netflix.hystrix.exception.HystrixRuntimeException:
GetBillingCommand short-circuited and no fallback available.- A fallback can issue another
HystrixCommand(like calling another failable service): we can cascade them as we want. - A
cacheKeycan be provided for Hystrix to cache the first response and return it directly on next calls. The values are kept in the currentHystrixRequestContext, which has normally a short-life: the one of the request. eg: If during a request, you retrieve a username throughGetUserNameCommand, and another part of the application calls it again 0.005ms later, you don’t expect it to change, so you cache it. - A command instance is cancellable if it was
queue().
There are more options on the circuit-breaker than the other solutions:
- We can limit the concurrency with a “semaphore” (its implementation in Hystrix is not a blocking one, and just rely on a
AtomicIntegerand atryAcquire: Boolean). - We can limit the max time the command takes (enabled by default! and if
execution.isolation.thread.interruptOnTimeoutistrue) before it throws aHystrixTimeoutException. - The circuit-breaker limits work on a time (
RollingStatisticalWindowInMilliseconds) and volume basis (RequestVolumeThreshold). There is a balance to find between them to ensure the circuit-breaker will be triggered or not.
Archaius
With Archaius (which is the configuration manager embedded in Hystrix), it’s possible to make the config available through JMX, and to modify it on the fly:
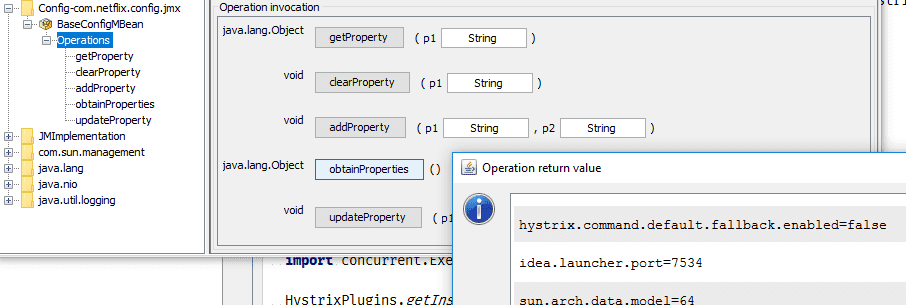
Archaius can also regularly poll any configuration storage (MySQL, Zookeeper, DynamoDB..) and notify the applications a property has changed. This is the purpose of Archaius’s DynamicProperty:
implicit def fnToRun[A](fn: => Unit): Runnable = new Runnable { override def run() = fn }
val key = "hystrix.command.default.circuitBreaker.enabled"
val prop: DynamicBooleanProperty = DynamicPropertyFactory.getInstance()
.getBooleanProperty(key, true, println(s"changed! ${prop.get}"))
ConfigurationManager.getConfigInstance.setProperty(key, true)
ConfigurationManager.getConfigInstance.setProperty(key, false)
// changed! true
// changed! falseIt’s quite powerful to have a dynamic centralized configuration database to be able to interact with the services on-the-fly.
For instance, it’s possible to manually open the circuit-breakers (if they have not force the default config value) with hystrix.command.default.circuitBreaker.forceOpen or disable the fallbacks hystrix.command.default.fallback.enabled, disable the caches, and so on. This can be useful for tests or during deployments.
All default Hystrix properties are detailed here.
Monitoring
It’s possible to get commands metrics with the contrib extension hystrix-metrics-event-stream, that originally exposes them through a Servlet. But we can just use a part of it and expose them wherever we want, as shown in the code below.
libraryDependencies += "com.netflix.hystrix" % "hystrix-metrics-event-stream" % "1.5.9"
libraryDependencies += "javax.servlet" % "javax.servlet-api" % "3.1.0"new HystrixMetricsPoller(new MetricsAsJsonPollerListener {
def handleJsonMetric(json: String) = println(json)
}, 1000).start()This will print metrics of all commands and thread pools (by command groups) every 1000ms:
{
"type": "HystrixCommand",
"name": "GetBillingCommand",
"group": "billing",
"currentTime": 1485640874974,
"isCircuitBreakerOpen": true,
"errorPercentage": 100,
"errorCount": 1,
"requestCount": 1,
...
}
{
"type": "HystrixThreadPool",
"name": "billing",
"currentTime": 1485640874980,
"currentActiveCount": 0,
"currentCompletedTaskCount": 1,
"currentCorePoolSize": 10,
...
}We can create dashboards and some alerting from those metrics if we send them into a proper monitoring system.
But HystrixMetricsPoller is actually deprecated, and internally, the plugin is using the new dedicated class available in the core package: HystrixDashboardStream.
It’s better because it relies on Observable, handles backpressure (drop), and we can just do whatever we want with them!
Here is a sample (with Scala Observables please):
libraryDependencies += "io.reactivex" %% "rxscala" % "0.26.5"import rx.lang.scala.JavaConverters._
import collection.JavaConverters._
// the interval is stored in the Archaius config, as expected
ConfigurationManager.getConfigInstance.setProperty(
"hystrix.stream.dashboard.intervalInMilliseconds", 1000)
// the "Dashboard" stream is the Hystrix metrics stream
val dataObs = HystrixDashboardStream.getInstance().observe().asScala
dataObs.subscribe(data => println(data.getCommandMetrics.asScala
.map(c => s"${c.getCommandGroup}:${c.getCommandKey}:${c.getHealthCounts}")
.mkString("|")
))That would output lines like this:
billing:get-billing:HealthCounts[1 / 1 : 100%]|billing:get-number:HealthCounts[2 / 7 : 28%]Hopefully, we can just get any metrics from the data, and output in our monitoring system or into Kafka for instance.
Dashboards
The main plugin of Hystrix is probably hystrix-dashboard, developed by Netflix.
It starts a webserver and displays the HystrixCommands metrics with some nice UI, to see what’s going on with the commands.
It helps to discover real-time situations and quickly trigger some recovery.
- To start the webserver, a simple option is to use Docker:
$ docker run -P -d mlabouardy/hystrix-dashboard:latest- We need to expose our application metrics.
To do that, we need to run the servlet “event-stream” from the extension we just saw: hystrix-metrics-event-stream.
We can start it quite easily without any XML crap using Jetty:
libraryDependencies += "org.eclipse.jetty" % "jetty-servlet" % "9.4.0.v20161208"val server = new Server(new InetSocketAddress("0.0.0.0", 8090))
val context2 = new ServletContextHandler(server, "/")
context2.addServlet(classOf[HystrixMetricsStreamServlet], "/hystrix.stream")
server.start()
...
server.join() // blockingThe webserver homepage looks like (http://localhost:32768/hystrix/):
We just have to provide the address of the events stream (SSE). That will listen to it and update in real-time (because SSE) the dashboard:
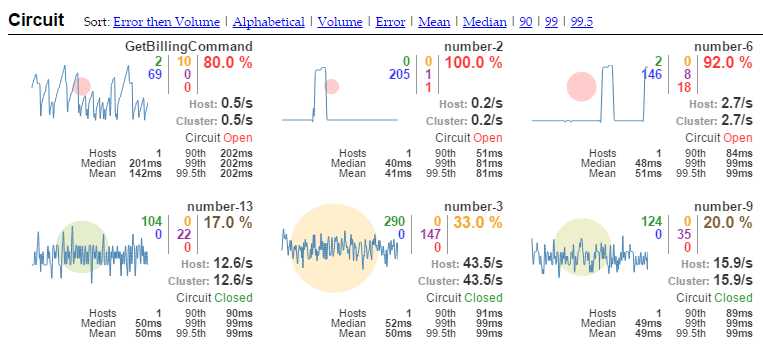

Each number has a tooltip when we hover them, hopefully.
We can see:
- Each command has its own “widget”.
- Which circuits are opened/closed.
- The ratio error/total of each command.
- The “volume” of each command (the circle).
- The purple number is the thread pool rejected request count.
- The thread pools activity (by
CommandGroup)
Anyway, very interesting to monitor the internals and be aware of any suspicious changes.
Hystrix is a complete framework to deal with services communications, it provides a lot of useful features, and is very stable and mature, thanks to the experience of Netflix’s teams.
A few resources to check:
- Application Resilience Engineering and Operations at Netflix with Hystrix: 148 slides!
- hystrix-play: Integration of Hystrix’s in a Play! application, provide the DashboardStream for monitoring.
Lagom
Let’s tackle the newcomer, by the Lightbend team: Lagom, and see how it deals with circuit-breakers.
http://www.lagomframework.com/documentation/1.2.x/java/ServiceClients.html#circuit-breakers
Stay tune! This is a work in progress.
