
Kafka has quite evolved since some times. Its consuming model is very powerful, can greatly scale, is quite simple to understand.
It has never changed from a external point of view, but internally, it did since Kafka 0.9, and the appearance of the __consumer_offsets.
Before that, consumers offsets were stored in Zookeeper. Now, Kafka is eating its own dog food, to scale better.
It’s definitely an implementation detail we should not care about nor rely on, because it can change anytime soon in the newer versions, but it’s also very interesting to know it’s there, what does it contains, how it is used, to understand the Kafka consuming model and its constraints.
We’ll start by looking at higher-level commands to check the offsets, then we’ll go deeper with the __consumer_offsets topic and the Offset Manager/Group Coordinator logic.
We’ll finish by a Kafka Streams processor to convert this topic to a JSON-readable topic to finally be consumed by a timeseries database (Druid), for monitoring and alerting purpose.
Summary
Eating its own dog food
The topic __consumer_offsets stores the consumers offsets (sic!). This provides a unique storage for the consumers to remember until which message they read and in case of failure, to restart from there. Note that each consumer is free to NOT use what Kafka provides and deal with the offsets themselves (and use the low-level consumer, asking for custom offsets).
Let’s resume the vocabulary around the Kafka’s consuming model, to understand what’s in the game:
- A consumer consumes the
partitionsof sometopics. (and can consume only a part of a topic partitions, to distribute the load among several consumers, thanks to the high-level consumer) - A consumer belongs to a
groupId. Note that the samegroupIdcan be used to consume different topics and are totally independent. - Each consumed partitions has its own last
offsetconsumed for each couple(topic, groupId).
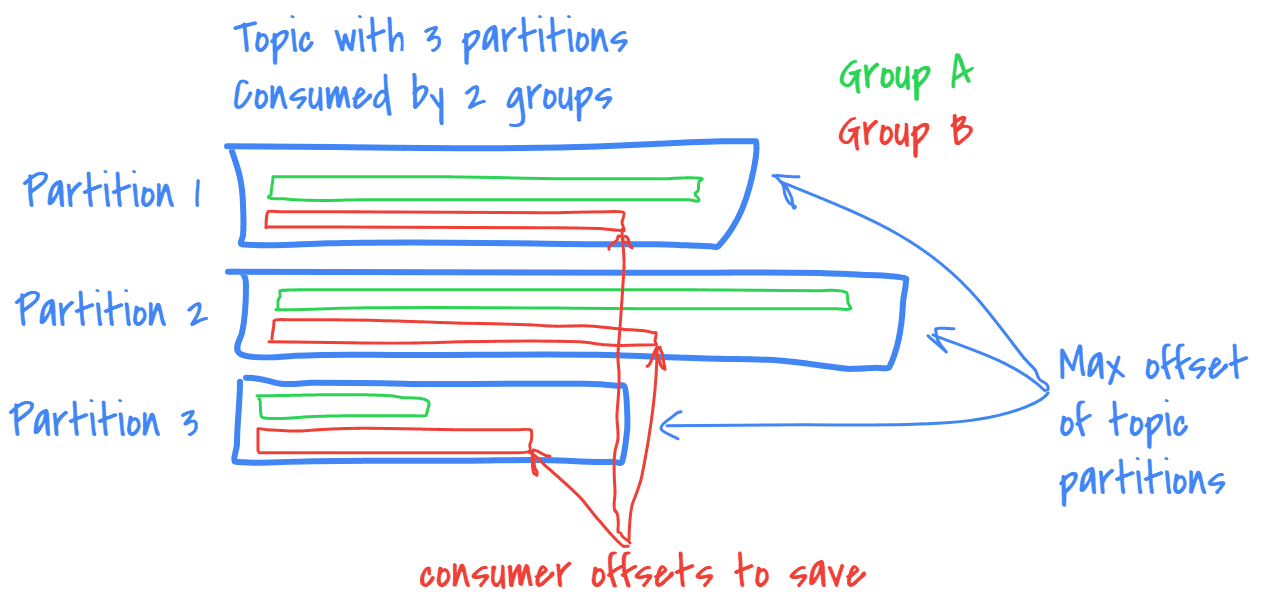
__consumer_offsets is the storage of all these things through time.
If we consume it, we can be aware of all the changes and progression of each consumers.
How to know the current offsets of a group?
Admin command: ConsumerGroupCommand
It’s probably the simplest human-friendly way to do so. We don’t even have to know it’s coming from this topic: the topic is an implementation detail after all. Moreover, it’s actually coming from a in-memory cache (which uses the topic as a cold storage).
Kafka has severals commands (available through the generic kafka-run-class script), here we care about ConsumerGroupCommand:
$ kafka-run-class kafka.admin.ConsumerGroupCommand
List all consumer groups, describe a consumer group, or delete consumer group info.
--bootstrap-server # Only with --new-consumer
--command-config <command config property file>
--delete
--describe
--group <consumer group>
--list
--new-consumer
--topic <topic> # Only used with --delete
--zookeeper <urls> # Only without --new-consumerA classic usage, to know how our consumer application behaves (it is fast?):
$ kafka-run-class kafka.admin.ConsumerGroupCommand --bootstrap-server localhost:9092 \
--group mygroup \
--new-consumer \
--describe
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG OWNER
mygroup mytopic 0 unknown 6971670 unknown consumer-1_/137.74.23.1
mygroup mytopic 1 6504514 6504514 0 consumer-1_/137.74.23.1
mygroup mytopic 2 unknown 6507388 unknown consumer-1_/137.74.23.1
mygroup mytopic 3 6175879 6969711 793832 consumer-1_/172.16.10.5
mygroup mytopic 4 unknown 6503476 unknown consumer-1_/172.16.10.5Note: some offsets are unknown (therefore the lag also) because the consumers did not consume all the partitions yet.
If this group is consuming several topics, all will be seen in the list.
I’m particularly fan of combining this with watch, to see the evolution without touching anything:
$ watch -n1 -t "kafka-run-class kafka.admin.ConsumerGroupCommand --bootstrap-server localhost:9092 \
--new-consumer --group extranet --describe 2>/dev/null"Legacy: migration from Zookeeper
Notice the --new-consumer and the Kafka’s broker address, it does not need a Zookeeper address as before.
If we did migrated from a previous Kafka version, according to the brokers configuration, Kafka can dual-writes the offsets into Zookeeper and Kafka’s __consumer_offsets (see dual.commit.enabled=true and offsets.storage=kafka).
[zk: zk:2181(CONNECTED) 7] get /consumers/console-consumer-86714/offsets/__consumer_offsets/20
18015941
...Post Kafka-0.8, Zookeeper is only used for the brokers management (failures, discovery), not for the offsets management.
Tip: summing-up the lag
When we have several partitions, it’s sometimes useful to just care about the sum of each partition’s lag (0 meaning the group has catched up the latest messages):
$ kafka-run-class kafka.admin.ConsumerGroupCommand --bootstrap-server localhost:9092 \
--new-consumer \
--group mygroup \
--describe 2>/dev/null | awk 'NR>1 { print $6 }' | paste -sd+ - | bc
98We know the whole group has only 98 events still not consumed. If this is a topic with tons of real-time events, that’s not bad!
Tip: listing all the active groups
This command is very useful to discover all the active groups on the cluster:
$ kafka-run-class kafka.admin.ConsumerGroupCommand --bootstrap-server localhost:9092 \
--new-consumer --list
money-streamers
monitoring
weatherNote that during a partition rebalancing, the affected group temporary disappears, because it is not active anymore.
Consuming __consumer_offsets
Because it’s a topic, it’s possible to just consume it as any other topic.
But because it’s an internal Kafka topic, by default, the consumers can’t see it, therefore they can’t consume it. We must ask them to not exclude it (default is true) by adding some props:
$ echo "exclude.internal.topics=false" > /tmp/consumer.configThen we use it to consume the topic:
$ kafka-console-consumer --consumer.config /tmp/consumer.config \
--zookeeper localhost:2181 \
--topic __consumer_offsetsOutput:
▒k ]▒▒▒▒ ]▒▒▒▒
▒kg ]▒▒▒▒ ]▒▒▒▒
▒▒▒ ]▒▒▒▒ ]▒▒▒▒WHAT KIND OF SORCERY IS THIS?
Because it’s saved as binary data, we need some kind of formatter to help us out:
$ kafka-console-consumer --consumer.config /tmp/consumer.config \
--formatter "kafka.coordinator.GroupMetadataManager\$OffsetsMessageFormatter" \
--zookeeper localhost:2181 \
--topic __consumer_offsetsHere it is:
[mygroup1,mytopic1,11]::[OffsetMetadata[55166421,NO_METADATA],CommitTime 1502060076305,ExpirationTime 1502146476305]
[mygroup1,mytopic1,13]::[OffsetMetadata[55037927,NO_METADATA],CommitTime 1502060076305,ExpirationTime 1502146476305]
[mygroup2,mytopic2,0]::[OffsetMetadata[126,NO_METADATA],CommitTime 1502060076343,ExpirationTime 1502146476343]We can’t really make any use of it (we’ll explain the content just after), except playing with some regexes. Would it be better to get some nice JSON instead? (yes!)
Note that each message in this topic has a key and a value. It’s very important, as we’ll see next in the following Compaction section.
Kafka Streams: convert it to JSON
I’ve written a Kafka’s Streams app that reads this topic and convert its (key, val) to another topic, JSON-readable.
The core of the code is:
builder.stream[Array[Byte], Array[Byte]](INPUT_TOPIC)
.map[BaseKey, Array[Byte]](baseKey)
.filter(otherTopicsOnly(conf.outputTopic()))
.map[OffsetKey, Array[Byte]](offsetKey)
.map[Array[Byte], String](toJson)
.to(Serdes.ByteArray, Serdes.String, conf.outputTopic())- consumes
__consumer_offsets - maps the content to the
BaseKeycase class - removes its own offsets to avoid an infinite loop
- collects only the
OffsetKey - serializes them to JSON

(Kafka Streams really needs a Scala API with more functions, such as collect and smart types inferring).
Edit: lightbend/kafka-streams-scala has been merged into Kafka Trunk so it should be good now.
A typical converted message is:
{
"topic":"mytopic1",
"partition":11,
"group":"console-consumer-26549",
"version":1,
"offset":95,
"metadata":"",
"commitTimestamp":1501542796444,
"expireTimestamp":1501629196444
}We can find back the info we saw just with a better presentation.
It’s a message saying that the group console-consumer-26549 which consumes the topic mytopic1 has read until the offset 95 of its partition 11.
The four other fields leads to some questions, what does they mean?
"version":1: the version 0 contained only a timestamp, and is deprecated."metadata":"": a String provided by the offset committer to store additional info."commitTimestamp":1501542796444: the time in millis of the commit request (before the offsets where effectively commited across replicas)."expireTimestamp":1501629196444: (commitTimestamp+offsets.retention.minutes) (default: 1 day)
If a consumer group is inactive during this period, and starts after the expiration, the coordinator won’t find any offsets and Kafka will rely on the consumer auto.offset.reset property, to know if it needs to start from earliest or latest. This is very important to know, to avoid some surprises.
What is a Group Coordinator / Offset Manager?
A Group Coordinator is an Offset Manager at the same time. It’s a broker which is the leader for a group, that caches and commits its consumers offsets.
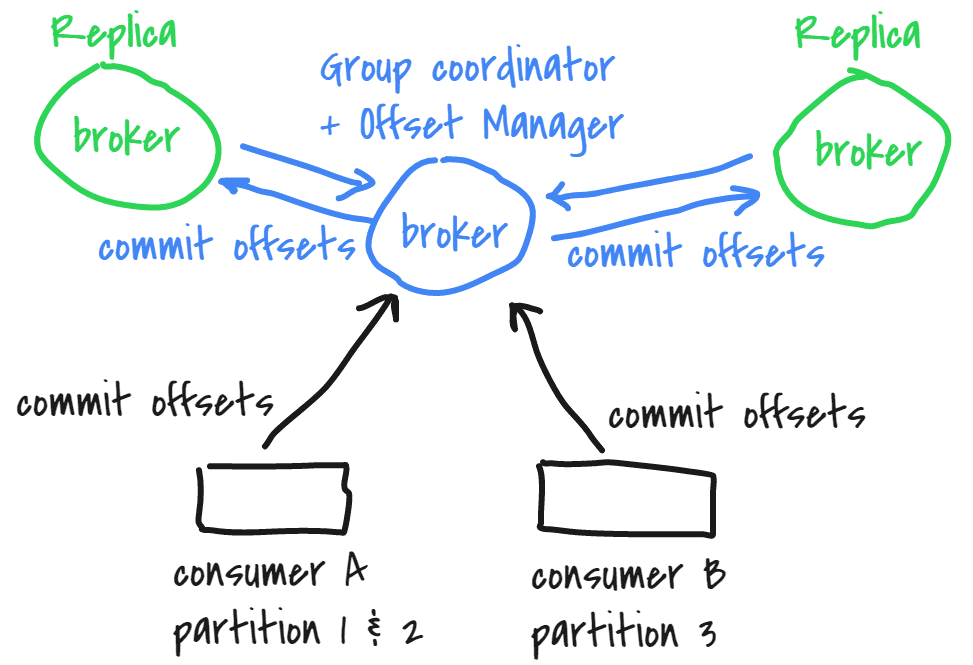
We can know which broker it is when using ConsumerGroupCommand:
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG OWNER
17/08/07 23:54:32 INFO internals.AbstractCoordinator: Discovered coordinator broker01:9092 (id: 2147483519) for group mygroupid.
...It’s also simple to find it programmatically:
Using Zookeeper to find the brokers, thanks to some Kafka client utils:
val channel = ClientUtils.channelToOffsetManager("mygroupid",
ZkUtils("zk:2181", 30000, 30000, false))
channel.disconnect()Through the logs, we can see what’s going on and who is the Offset Manager:
- Created socket with SO_TIMEOUT = 3000 (requested 3000), SO_RCVBUF = 65536 (requested -1), SO_SNDBUF = 65536 (requested -1), connectTimeoutMs = 3000.
- Created channel to broker broker03:9092.
- Querying broker03:9092 to locate offset manager for mygroupid.
- Consumer metadata response: GroupCoordinatorResponse(Some(BrokerEndPoint(128,broker01,9092)),NONE,0)
- Connecting to offset manager broker01:9092.Or at a lower level, by querying ourself a broker:
var channel = new BlockingChannel("broker03", 9092, UseDefaultBufferSize,
UseDefaultBufferSize, readTimeoutMs = 5000)
channel.connect()
channel.send(GroupCoordinatorRequest("mygroupid"))
val metadataResponse = GroupCoordinatorResponse.readFrom(channel.receive.payload())
println(metadataResponse)
channel2.disconnect()GroupCoordinatorResponse(Some(BrokerEndPoint(128,broker01,9092)),NONE,0)Note: None corresponds to Errors and the 0 is the correlationId (a distinct ID per request, to know to which one it corresponds).
In code: GroupCoordinator and GroupMetadataManager
Both classes deal with offsets commits, and everything related to the group management.
GroupMetadataManager responds to the offsets queries and store the latest consumer offsets for the group it manages in a local cache.
When an offset commit is asked by a client, the Group Coordinator waits for the replicas (generally, it’s set to 3) to commit the offsets, to ensure it’s properly committed everywhere before responding to the client. In case of failure, nothing is committed and an error is returned to the client, that must retry.
Compaction
__consumer_offsets is a compacted topic. It’s useful to not consume too many disk space for no reason, because we don’t care of the past state. The compaction is only possible because this topic has a fixed key for the same event: the combinaison (group, topic, partition number).
The purpose of the __consumer_offsets topic is to keep the latest consumed offset per group/topic/partition, which is why the key is the combinaison of them. Through the compaction, only the latest value will be saved into Kafka’s data, the past offsets are useless. It’s a complement to the auto-cleaning done via the expireTimestamp.
Ingest the JSON into Druid
Let’s use our JSON topic to fulfill a timeseries database!
We’re going to use Druid because it’s a very good and realtime-json-ingestion-friendly database.
We’ll use it Kafka Supervisor extension to listen to our Kafka __consumer_offsets_json topic in realtime and see the result in Pivot.

First, we need to tell Druid where and how to read our Kafka topic through some json specification.
We’ll set what are the names of the fields, which one is the timestamps, which ones are the dimensions, and which ones are the metrics:
{
"type": "kafka",
"dataSchema": {
"dataSource": "consumer-offsets",
"parser": {
"type": "string",
"parseSpec": {
"format": "json",
"timestampSpec": { "column": "commitTimestamp", "format": "auto" },
"dimensionsSpec": { "dimensions": [ "topic", "partition", "group" ] }
}
},
"metricsSpec": [
{ "type": "count", "name": "count" },
{ "type": "doubleSum", "name": "offset", "fieldName": "offset" }
],
"granularitySpec": {
"type": "uniform",
"segmentGranularity": "DAY",
"queryGranularity": "MINUTE"
}
},
"tuningConfig": {
"type": "kafka"
},
"ioConfig": {
"topic": "consumer_offsets_json",
"consumerProperties": {
"bootstrap.servers": "kafka01:9092"
}
}
}We can then use Pivot to see what’s going on:
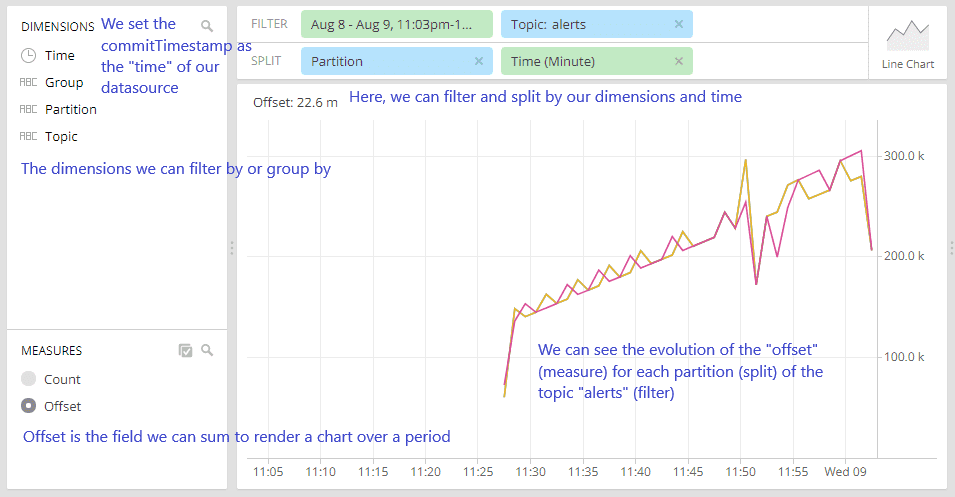
It’s also possible to group by groupId, or both groupId and topic, according to your needs.
Moreover, Pivot is not mandatory to query Druid. Everywhere goes through a JSON API (and SQL API since Druid 0.10.x).
$ curl -X POST 'http://druidbroker:8082/druid/v2/?pretty=' \
-H 'content-type: application/json' \
-d '{
"queryType": "timeseries",
"dataSource": "kafkaoffsets",
"granularity": "minute",
"descending": "true",
"filter": { "type": "selector", "dimension": "group", "value": "super-streamer" },
"aggregations": [
{ "type": "longSum", "name": "offset", "fieldName": "offset" }
],
"postAggregations": [],
"intervals": [ "2017-08-09/2017-08-10" ]
}'[
{
"timestamp": "2017-08-09T00:26:00.000Z",
"result": {
"offset": 231966
}
},
{
"timestamp": "2017-08-09T00:25:00.000Z",
"result": {
"offset": 1312911
}
},
...
]Thanks to this, it’s possible to easily keep track of the evolution of all the consumer offsets. It does not take a lot of space because Druid mostly works on aggregated data (see the queryGranularity to MINUTE in the spec here).
It’s possible to use its query engine to trigger some alerts on a particular group or topic (if we didn’t get any changes since 2min for instance). Only the sky’s the limit.
Conclusion
If we resume:
__consumer_offsetsis an implementation detail (came in 0.9) we should not rely on; it replaces the old system based on Zookeeper.__consumer_offsetsis binary encoded. It keeps the latest consumed offsets for each topic/group/partition for a certain time only (1d).ConsumerGroupCommandcan be used to retrieve the consumers offsets.- There is one broker that deals with offset commits: the GroupCoordinator / OffsetManager.
- Low-level consumers can choose to not commit their offsets into Kafka (mostly to ensure at-least/exactly-once).
- Kafka Streams is excellent at filling a topic from another one.
- Druid is excellent at ingesting timestamped JSON.
